
突破模擬計算世紀難題!北京大學團隊成功研制新型芯片
關鍵詞: 模擬矩陣計算芯片 模擬計算精度 阻變存儲器 北京大學
近日,北京大學人工智能研究院孫仲研究員團隊聯合集成電路學院研究團隊,成功研制出基于阻變存儲器的高精度、可擴展模擬矩陣計算芯片,首次實現了在精度上可與數字計算媲美的模擬計算系統。相關論文于10月13日刊發于《自然·電子學》期刊。
研究團隊成功研制出基于阻變存儲器的高精度、可擴展模擬矩陣計算芯片,首次實現了在精度上可與數字計算媲美的模擬計算系統,將傳統模擬計算的精度提升了驚人的5個數量級。相關性能評估表明,該芯片在求解大規模MIMO信號檢測等關鍵科學問題時,計算吞吐量與能效較當前頂級數字處理器(GPU)提升百倍至千倍。
據北京大學消息,這一成果標志著我國突破模擬計算世紀難題,在后摩爾時代計算范式變革中取得重大突破,為應對人工智能與6G通信等領域的算力挑戰開辟了全新路徑。
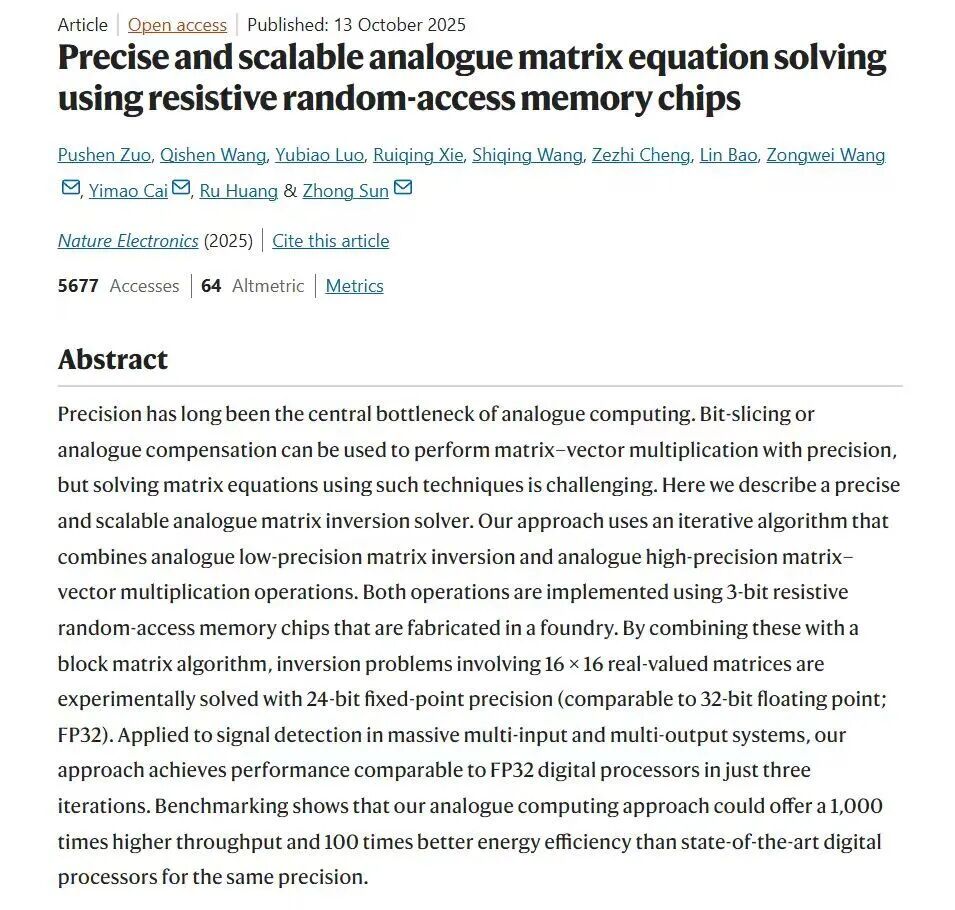
孫仲表示,現在的所有芯片都是數字計算,數據都需要先轉換成0和1的符號串。而模擬計算則無需這層“轉譯”,它是一種類比計算,可以直接用連續的物理量(如電壓、電流)來類比數學上的數字。
模擬計算機在計算機發展早期(上世紀30-60年代)曾被廣泛應用,但隨著計算任務日益復雜,其精度瓶頸凸顯,逐漸被數字計算取代。孫仲指出,此次研究的核心正是要解決模擬計算“算不準”這一痛點。
當前的市面上的主流CPU和GPU都是數字芯片,并都采用馮諾依曼結構,將計算和存儲功能分開,通過01數字流的編譯+計算+解碼實現信息計算和傳輸。
基于阻變存儲器的模擬計算的優勢之一在于取消了“將數據轉化為二進制數字流”這一過程,同時不必進行“過程性數據存儲”,進而將數據計算過程與數據存儲合而為一,實現算力解放。
孫仲指出,與其他“存算一體”方案對比,國內外許多團隊集中于研究矩陣乘法(AI推理的核心),而他的團隊特色在于專注于更具挑戰性的矩陣方程求解(AI二階訓練的核心)。矩陣求逆操作要求的計算精度極高,時間復雜度達到了立方級。而模擬計算憑借物理規律直接運算的方式,具有低功耗、低延遲、高能效、高并行的天然優勢,只要能夠不斷降低計算誤差,不斷提升計算精度,將為傳統GPU的算力解放帶來爆炸性突破。
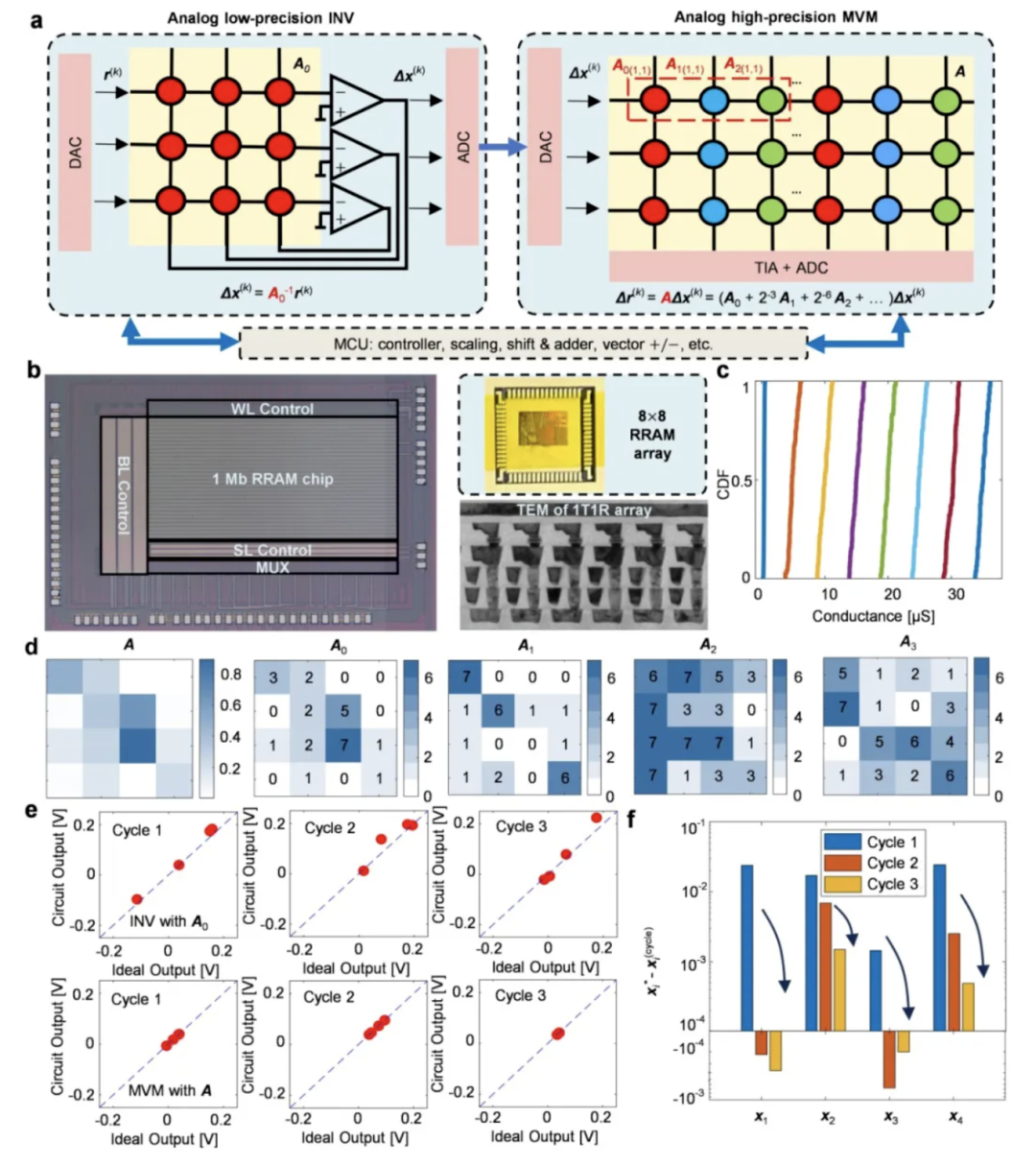
在計算精度方面,團隊在實驗上成功實現16×16矩陣的24比特定點數精度求逆,矩陣方程求解經過10次迭代后,相對誤差可低至10??量級。
在計算性能方面,該技術表現出卓越的加速能力與能效。測試結果表明,在求解32×32矩陣求逆問題時,其算力已超越高端GPU的單核性能;當問題規模擴大至128×128時,計算吞吐量更達到頂級數字處理器的1000倍以上,傳統GPU干一天的活,這款芯片一分鐘就能搞定。同時,該方案在能效方面亦表現突出,在相同精度下能效比傳統數字處理器提升超100倍,為高能效計算中心提供了關鍵技術支撐。
據人民日報報道,關于應用前景,孫仲認為,模擬計算在未來AI領域的定位是強大的補充,最有可能快速落地的場景是計算智能領域,如機器人和人工智能模型的訓練。談及與現有計算架構的關系,孫仲強調未來將是互補共存:“CPU作為通用‘總指揮’因其成熟與經濟性而難以被淘汰。GPU則專注于加速矩陣乘法計算。我們的模擬計算芯片,旨在更高效地處理AI等領域最耗能的矩陣逆運算,是對現有算力體系的有力補充。”






